Deep lidar CNN to understand the dynamics of moving vehicles
Deep lidar CNN to understand the dynamics of moving vehicles
Abstract
Perception technologies in Autonomous Driving are experiencing their golden age due to the advances in Deep Learning. Yet, most of these systems rely on the semantically rich information of RGB images. Deep Learning solutions applied to the data of other sensors typically mounted on autonomous cars (e.g. lidars or radars) are not explored much. In this paper we propose a novel solution to understand the dynamics of moving vehicles of the scene from only lidar information. The main challenge of this problem stems from the fact that we need to disambiguate the proprio-motion of the “observer” vehicle from that of the external “observed” vehicles. For this purpose, we devise a CNN architecture which at testing time is fed with pairs of consecutive lidar scans. However, in order to properly learn the parameters of this network, during training we introduce a series of so-called pretext tasks which also leverage on image data. These tasks include semantic information about vehicleness and a novel lidar-flow feature which combines standard image-based optical flow with lidar scans. We obtain very promising results and show that including distilled image information only during training, allows improving the inference results of the network at test time, even when image data is no longer used.

Paper Summary
In this paper we propose a novel approach to detect the motion vector of dynamic vehicles over the ground plane by using only lidar information. Detecting independent dynamic objects reliably from a moving platform (ego vehicle) is an arduous task. The proprio-motion of the vehicle in which the lidar sensor is mounted needs to be disambiguated from the actual motion of the other objects in the scene, which introduces additional difficulties.
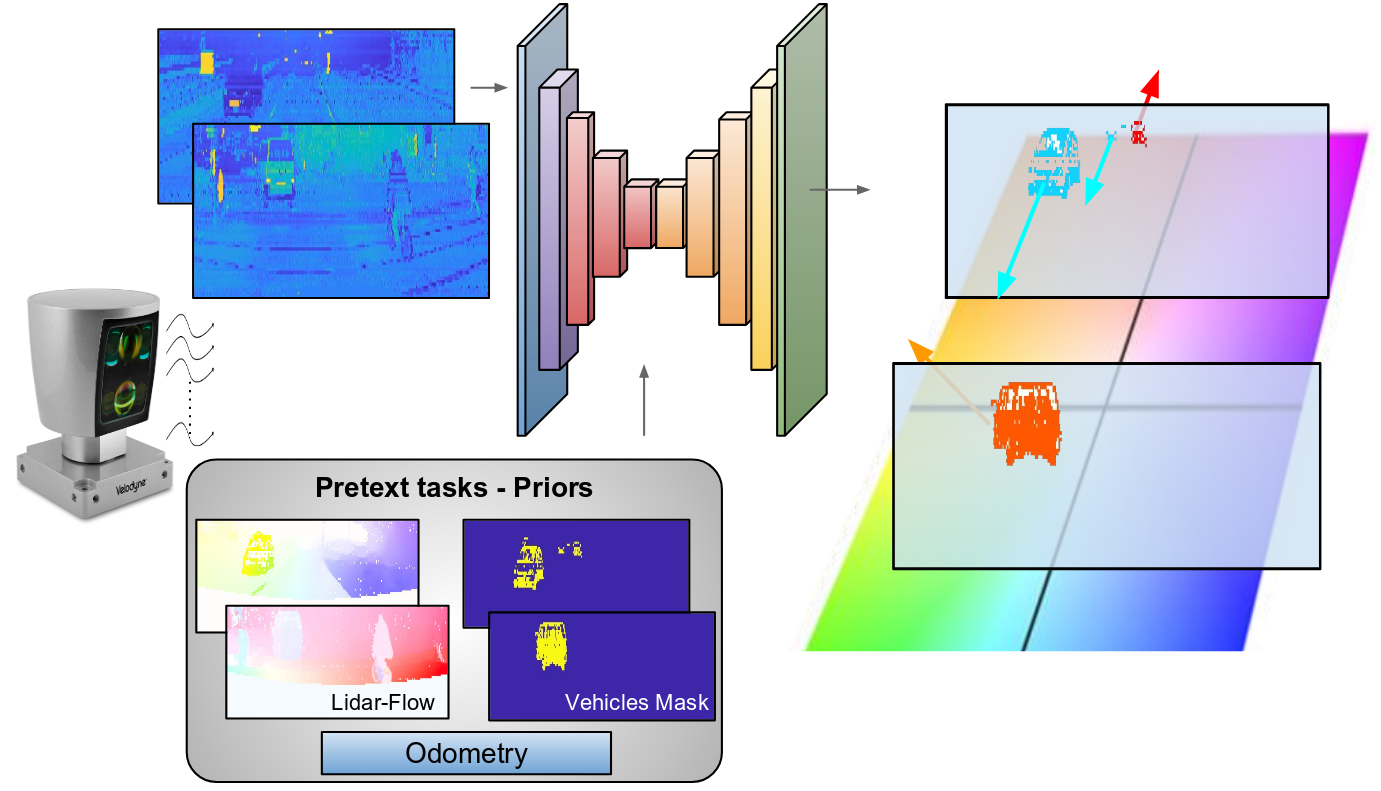
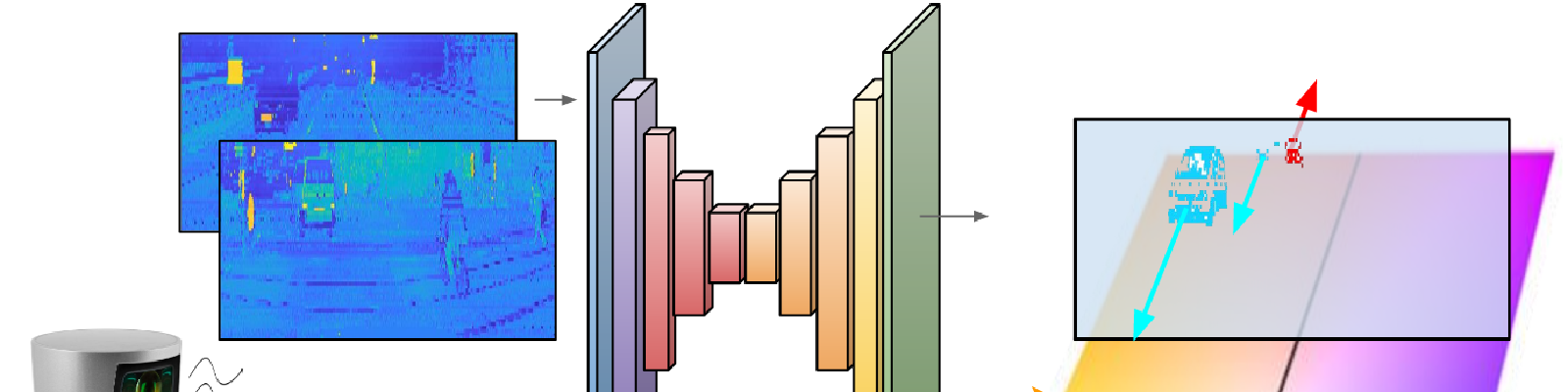
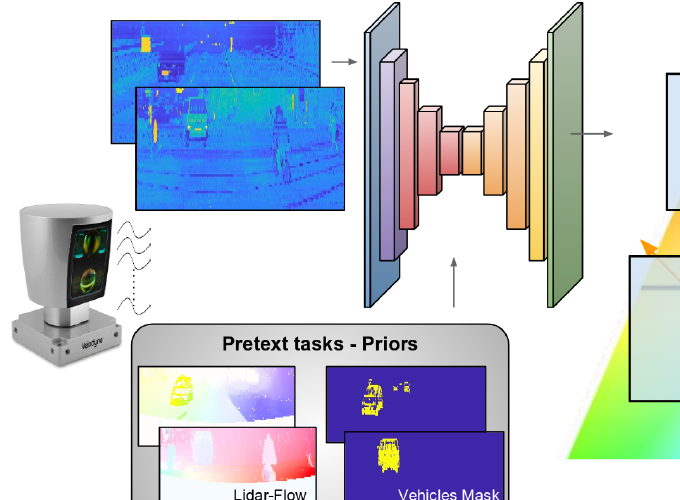
We present a deep learning approach that, using only lidar information, is able to estimate the ground-plane motion of the surrounding vehicles. In order to guide the learning process we introduce to our deep framework prior semantic and pixel-wise motion information, obtained from solving simpler pretext tasks, as well as odometry measurements.
We tackle this challenging problem by designing a novel Deep Learning framework. Given two consecutive lidar scans acquired from a moving vehicle, our approach is able to detect the movement of the other vehicles in the scene which have an actual motion with respect to a “ground” fixed reference frame. During inference, our network is only fed with lidar data, although for training we consider a series of pretext tasks to help with solving the problem that can potentially exploit image information.
Information Representation
Input Data
The input of the network corresponds to a pair of lidar scans, which are represented in 2D domains of range and reflectivity, as in our Deep Lidar paper.

The output we seek to learn represents the motion vectors of the moving vehicles, colored here with the shown pattern attending to the motion angle and magnitude.

Pretext tasks
We introduce a novel lidar-flow feature that is learned by combining lidar and standard image-based optical flow. In addition, we incorporate semantic vehicleness information from another network trained on singe lidar scans. Apart from these priors, we introduce knowledge about the ego motion by providing odometry measurements as inputs too.
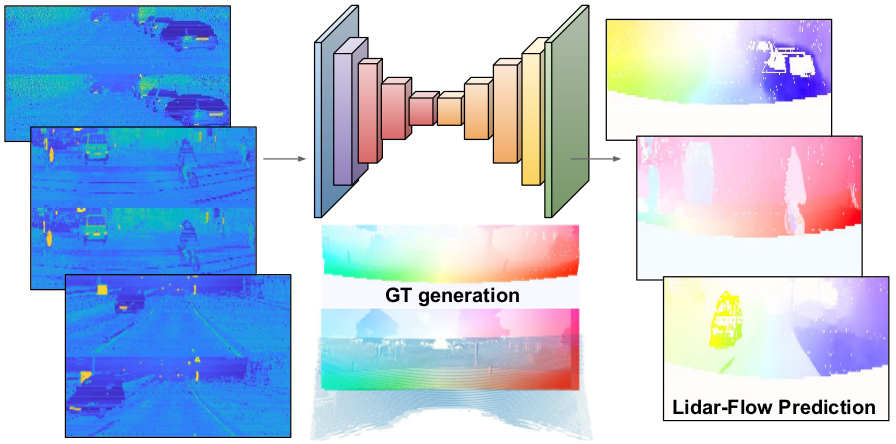
Lidar-flow prior, obtained by processing pairs of frames through a new learned lidar-flow net.
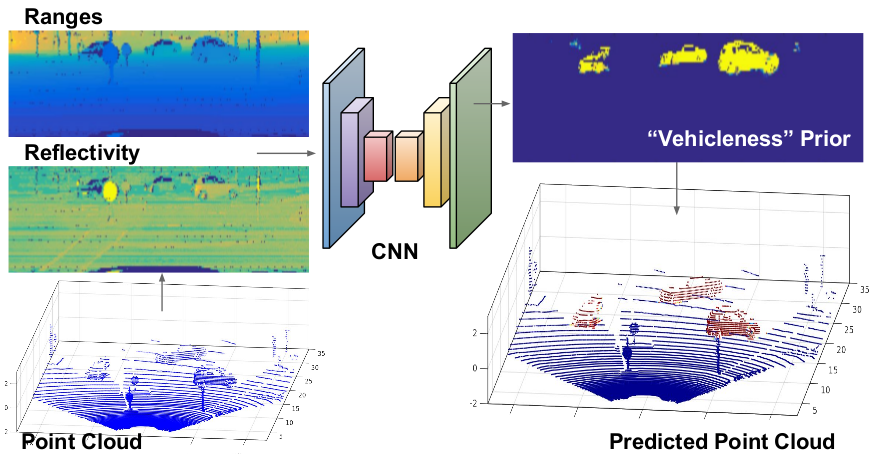
Semantic prior, obtained by processing single frames through our vehicle lidar-detector net.
Network
Our architecture performs a concatenation between equally sized feature maps from the contractive and the expansive parts of the network which produce richer representations and allows better gradient flow. In addition, we also impose intermediate loss optimization points obtaining results at different resolutions which are upsampled and concatenated to the immediate upper feature maps, guiding the final solution from early steps and allowing the back-propagation of stronger and healthier gradients.

Results
We demonstrate the correct performance of our framework by setting two different baselines, error@zero and error@mean. The first one assumes a zero regression, so that sets all the predictions to zero as if there were no detector. The second baseline measures the end-point-error that a mean-motion output would obtain.
We also measure end-point error over the real dynamic points only. Both measurements are indicated as full and dynamic. All the given values are calculated at test time over the validation set only, which during the learning phase has never been used for training neither the main network nor the pretext tasks. Recall that during testing, the final networks are evaluated only using lidar Data.
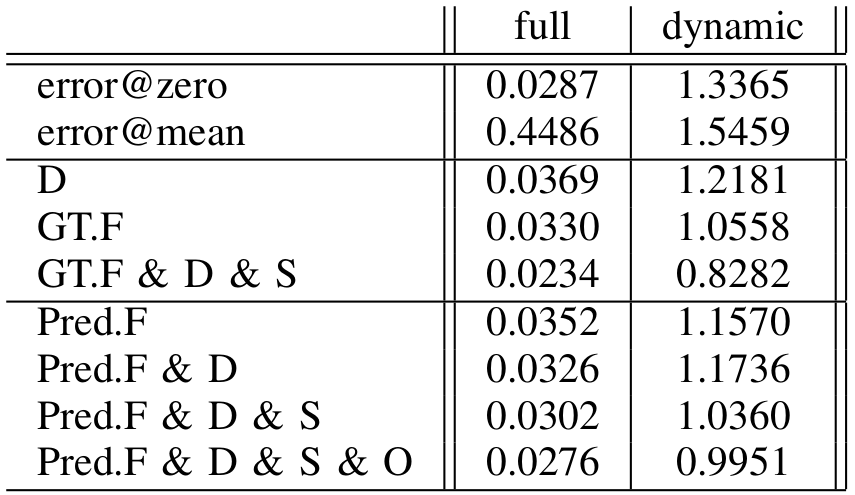
Quantitative evaluation using several combination of lidar- and image-based priors. D, F , S and O respectively for models using Data, Lidar-Flow, Vehicle Segmentation and Odometry. Test is performed using only lidar inputs. Errors are measured in pixels, end-point-error.
To account for the strength of introducing optical flow as motion knowledge for the network, we tested training with only the lidar-flow ground truth (GT.F rows in the table) as well as with a combination of flow ground-truth, semantics and lidar data. Both experiments show favourable results, being the second one the most remarkable. However, the lidar-flow ground-truth is obtained from the optical flow extracted using RGB images, which does not accomplish our solo-lidar goal. We therefore perform the rest of experiments with the learned lidar-flow (Pred.F rows in the table) as prior, eliminating any dependence on camera images.
Acknowledgements: This work has been supported by the Spanish Ministry of Economy and Competitiveness projects HuMoUR (TIN2017-90086-R) and COL- ROBTRANSP (DPI2016-78957-R) and the Spanish State Research Agency through the Marı́a de Maeztu Seal of Excellence to IRI (MDM-2016-0656). The authors also thank Nvidia for hardware donation under the GPU grant program.
