Joint Coarse-and-Fine Reasoning for Deep Optical Flow
Joint Coarse-and-Fine Reasoning for Deep Optical Flow
Abstract
We propose a novel representation for dense pixel-wise estimation tasks using CNNs that boosts accuracy and reduces training time, by explicitly exploiting joint coarse-and-fine reasoning. The coarse reasoning is performed over a discrete classification space to obtain a general rough solution, while the fine details of the solution are obtained over a continuous regression space. In our approach both components are jointly estimated, which proved to be beneficial for improving estimation accuracy. Additionally, we propose a new network architecture, which combines coarse and fine components by treating the fine estimation as a refinement built on top of the coarse solution, and therefore adding details to the general prediction. We apply our approach to the challenging problem of optical flow estimation and empirically validate it against state-of-the-art CNN-based solutions trained from scratch and tested on large optical flow datasets.

Paper Summary

We approach dense per-pixel regression problems with a joint coarse-and-fine method and apply it to the challenging problem of optical flow prediction. Our method explicitly combines a coarse result based on the solution of pixel-wise horizontal and vertical classification problems with a fine one obtained through regression predictions.
Network Used

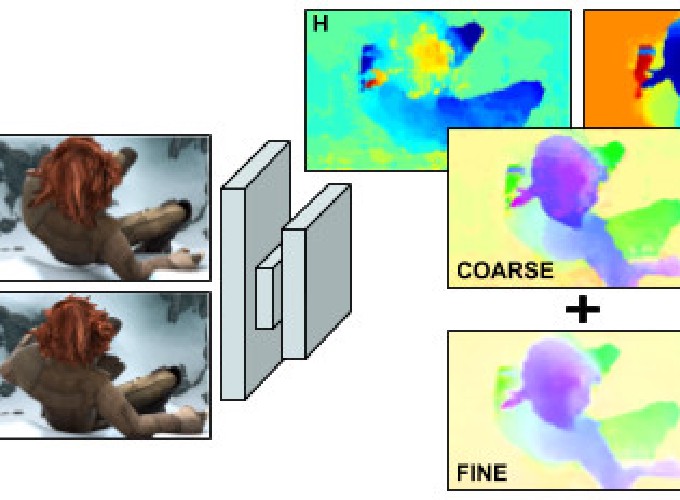
Our regularised FlowNet architecture is formed of a contractive and an expansive part. First, a set of Convolutions, Batch Normalization and Relu layers (CONV, BN and RELU) are interleaved to obtain abstract and hierarchical representations while contracting the input information. The final dense predictions is generated by deconvolution layers (CONV T ), and guided to an optimal solution by concatenating (CAT blocks) corresponding initial feature maps and the partial coarse and fine upsampled (Up) solutions obtained at five resolution points.
Coarse And Fine Module
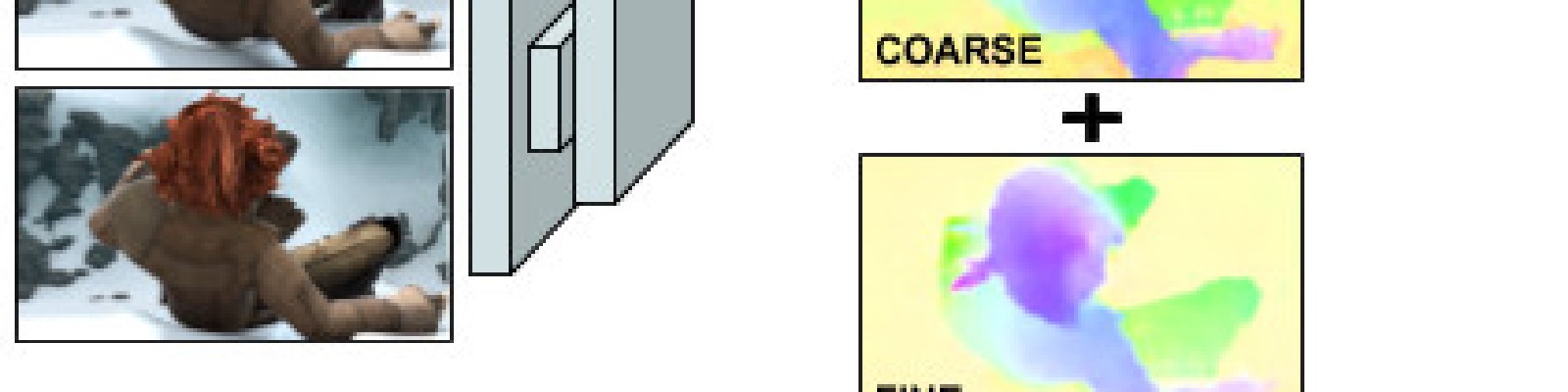
 Each coarse-and-fine module solves one regression and two classification per-pixel problems. Softmax outputs from these last are declassified obtaining the coarse solution.
Each coarse-and-fine module solves one regression and two classification per-pixel problems. Softmax outputs from these last are declassified obtaining the coarse solution.
Results
 Evaluation of the end-point-error for the presented models. Suffixes Kc indicate the number of classes used during training on Flying Chairs.
Results over the Sintel Training and Test sets are presented, showing the generalization of our method on unseen datasets.
Evaluation of the end-point-error for the presented models. Suffixes Kc indicate the number of classes used during training on Flying Chairs.
Results over the Sintel Training and Test sets are presented, showing the generalization of our method on unseen datasets.
Acknowledgements: This work was partially supported by European AEROARMS project (H2020-ICT-2014-1-644271) and CICYT projects ColRobTransp (DPI2016-78957-R), ROBINSTRUCT (TIN2014-58178-R). Authors thank Nvidia for GPU hardware donation.
